

Além de serem componentes fundamentais para o funcionamento do sistema, é nos HDs e SSDs que ficam guardadas muitas das suas informações mais importantes. São dispositivos constantemente exigidos pelo Windows e, apesar de apresentarem alta durabilidade, é sempre essencial manter atenção à integridade deles para evitar surpresas desagradáveis e possíveis perdas de dados.
Por esse motivo, tanto os discos rígidos (HDs) quanto as unidades de estado sólido (SSDs) utilizam a tecnologia S.M.A.R.T. — sigla para Self-Monitoring, Analysis, and Reporting Technology. Em português, trata-se de um sistema de automonitoramento que avalia, analisa e relata vários indicadores de confiabilidade da unidade. A ideia é permitir que você identifique sinais de desgaste ou falha antes que o problema se torne crítico.
Neste tutorial, vamos acessar, visualizar e interpretar esses dados de forma simples, destacando a condição principal do seu dispositivo. Para isso, utilizaremos o leve e eficiente CrystalDiskInfo, um programa totalmente capaz de apresentar esses indicadores de maneira clara e fácil de entender.
Passo 1: Baixe o CrystalDiskInfo por meio deste link e faça a instalação no seu computador.
Passo 2: Com o programa instalado, abra o atalho criado na área de trabalho e localize a seção “Status de Saúde”, conforme mostrado abaixo. Vale lembrar que ele também detecta HDs externos.
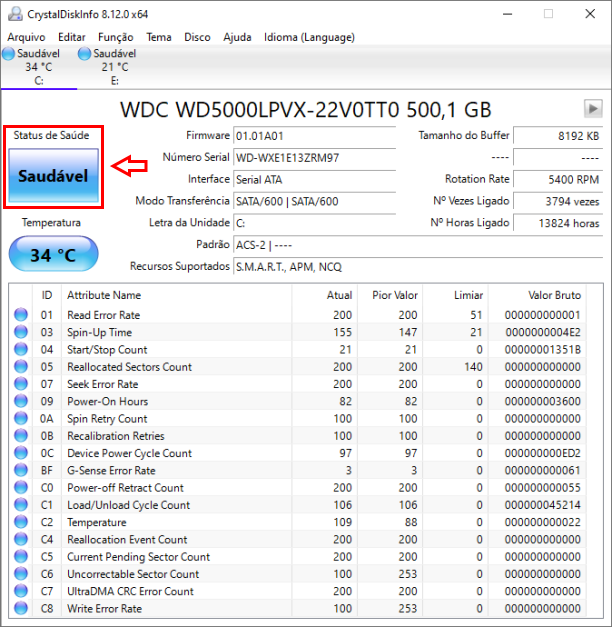
Observação: O indicador “Status de Saúde” pode apresentar quatro situações diferentes, de acordo com a documentação oficial:
- Saudável: o dispositivo está em perfeitas condições de uso;
- Alerta: indica possível desgaste; a interpretação depende dos atributos que acionaram o aviso;
- Crítico: aponta uma situação grave, com risco de falha iminente;
- Desconhecido: ocorre quando o sistema S.M.A.R.T. não está disponível ou não pode ser acessado.
Observação 2: Os atributos S.M.A.R.T. variam conforme o fabricante e o dispositivo, mas abaixo estão alguns dos mais importantes. Os considerados críticos estão destacados em vermelho. Os textos foram baseados no artigo da Wikipédia, caso você queira consultar informações ainda mais detalhadas.
- Read Error Rate: Indica a taxa de erros de leitura ocorridos no disco. O valor bruto varia entre fabricantes e nem sempre é interpretado diretamente como número decimal.
- Spin-Up Time: Tempo necessário para o disco rígido atingir sua velocidade de operação.
- Start/Stop Count: Número total de ciclos de liga/desliga do disco.
- Reallocated Sectors Count: Quantidade de setores defeituosos já remapeados. Quanto maior esse valor, maior o desgaste do disco e maior o risco de falhas.
- Seek Error Rate: Taxa de erros de movimentação das cabeças de leitura.
- Power-On Hours: Total de horas de funcionamento contínuo do dispositivo.
- Spin Retry Count: Número de tentativas adicionais necessárias para o disco iniciar sua rotação.
- End-to-End Error / IOEDC: Erros detectados no caminho dos dados entre a memória cache e a mídia.
- Reported Uncorrectable Errors: Contagem de erros que não puderam ser corrigidos pelo sistema de correção de erros (ECC).
- Hardware ECC Recovered: Número de erros corrigidos pelo ECC, variando conforme o fabricante.
- Command Timeout: Quantidade de comandos cancelados por tempo excedido. Idealmente deve permanecer em zero.
- Temperature: Temperatura atual da unidade.
- Reallocation Event Count: Número de tentativas de remapeamento de setores defeituosos.
- Current Pending Sector Count: Quantidade de setores instáveis aguardando remapeamento.
- Uncorrectable Sector Count: Erros graves de leitura/gravação impossíveis de corrigir.
- UltraDMA CRC Error Count: Número de erros na transferência de dados via cabo de interface.
- Write Error Rate: Quantidade de erros durante gravação.
- Soft Read Error Rate / TA Counter Detected: Erros irrecuperáveis de leitura em nível de software.
{kind=link}
Valeu!!!!